
Claude Fable 5 found a live bug on my site on day one, so I made it compete with Opus and Sonnet
I let Claude Fable 5, Opus 4.8 and Sonnet 4.6 each audit my own site's repo. Fable found a live failover bug, Opus 4.8 caught nearly as much for a third of the cost, Sonnet missed it. Scores, costs, fix: all public.
GTM Architect & Growth Operator · Now · 9 June 2026
TL;DR · Key insights
- Fable 5 and Mythos 5 are the same model. The safeguards are the only difference: Fable quietly falls back to Opus 4.8 on flagged topics, Mythos runs with some lifted for vetted partners.
- I let Fable 5, Opus 4.8 and Sonnet 4.6 each audit this site's repo, scored against six bugs I had verified by hand first. Fable found the most, including a live production bug in my DNS failover. Opus 4.8 caught nearly as much for a third of the cost per bug. Sonnet missed it. The fix is a public commit, linked below.
- It costs 2x Opus 4.8: $10 in, $50 out per million tokens. Worth it only if it finishes a job in fewer steps. Cost per result, not cost per token.
- The catch nobody puts on the slide: a silent fallback means two models can answer in one session. If you run agent loops, log which one replied or your numbers lie.
Anthropic shipped two frontier models today, June 9, 2026: Claude Fable 5 and Claude Mythos 5. One is for everyone. One is locked behind a trusted access program. Underneath, they are the same model.
The launch post is wall to wall benchmarks. I am not going to recap them. I run a business on Claude, not a leaderboard, and the only question I care about is what a stronger model does to the systems I already operate. This site in eight languages. The content pipeline. The agent loops that touch a CRM. Here is that answer, on my own work, with the receipts you can clone and run.
| Model | Score / 11 | Cost / found bug | In one line |
|---|---|---|---|
| Claude Fable 5 | 8.5 | $0.30 | Found the most, and the only one to catch the live failover bug in full |
| Claude Opus 4.8 | 8.0 | $0.11 | Caught nearly as much for a third of the cost per bug: cheapest per result |
| Claude Sonnet 4.6 | 1 | $0.76 | Missed the big one, but surfaced a real bug outside my answer key |
The whole benchmark in one table. Per-finding scores, costs and the exact method are further down.
Fable 5 and Mythos 5: two models, one brain
The naming is the tell. Anthropic says fable comes from the Latin fabula, “that which is told,” close to the Greek mythos. Same root, two masks. The difference is not capability. It is what the model is allowed to do.

Claude Fable 5 is on the API and every plan today. Safeguards on. When a request hits a flagged topic it does not refuse, it quietly answers with Opus 4.8 instead. Anthropic says this happens in under 5% of sessions.
Claude Mythos 5 is the same underlying model, some safeguards lifted. Restricted to vetted cyberdefenders through Project Glasswing, with a biology program to follow. Anthropic calls it the strongest cyber model it has built.
This is the one launch detail that touches anyone building on the API. A silent fallback is better UX than a hard refusal. It also means two different models can answer inside one session. If you run evals or agent loops, you want to log which one replied, or your numbers quietly mix two models.
What already runs on Claude here
Before I tell you what Fable changes, here is what it is changing. This site is not a brochure. It is a system, and Claude is load-bearing inside it.
It runs on Astro and Cloudflare, serverless, nothing to babysit. The site ships in eight languages through a DeepL pipeline I built, with a brand-protection layer so the translator never turns “Opus” into a common noun. That pipeline has produced 89 localized article versions across seven languages, every one of them sitting in this repo’s content collections where you can count them. The discovery layer, llms.txt, stays current so models can find the work. None of that is a demo. It is in the repo behind this page.
| Metric | Value | Info |
|---|---|---|
| Languages | 8 | EN plus 7, from one source edit |
| Pages built | 180 | every deploy passes CI |
| Tests | 560 | schema, links, build |
| Servers | 0 | Astro on Cloudflare, serverless |
This site as it builds today. Clone the repo and you get the same numbers.
One real job, eight languages, one session
The pricing comparison further down this page: here is how it got made, today, in one sitting. This is the kind of work I mean.
- One edit, in English. Wrote the pricing comparison once, in the canonical language, as the only source of truth.
- A surgical splice, not a re-translation. A script translated only the new block into seven languages and slotted it under the right heading, leaving every existing hand-fixed translation untouched.
- The part no launch post shows. It took four passes. DeepL read “credits” as film credits, “model card” as an RPG character sheet, “$5 input, $25 output” as buy and sell prices. I read every line and fixed the meaning. The model did the volume, I owned the judgment.
- Shipped. The build passing, 560 tests, pushed to main. Eight languages consistent. One session.
The translator handled eight languages in seconds. It also got the meaning wrong four times. Neither of those is a surprise, and both are the job. A stronger model shifts that line: fewer passes, less of my judgment spent on cleanup.
The three surfaces Claude Fable 5 has to survive: chat, agents, code
Same model, three very different jobs. Fast judgment in a chat window. A long multi-step run in a cowork agent. Code in this repo. The failure mode is different in each, and a frontier model is only worth the price if it holds up across all three.
One real task per surface
The same model has to be good at three different jobs, and each one breaks differently.
Score an inbound lead against my ICP and draft a two-line opener. Stresses judgment and concision in a single turn.
Take five LinkedIn URLs, enrich each, draft a personalised sequence, log it to the CRM. Stresses long-horizon tool use with no drift over many steps.
Refactor a content collection across this repo and keep the build passing. Stresses multi-file context held to the end, not just the first edit.
The code surface is the one with receipts, because it runs here and the numbers are public. To compare models honestly I had Claude build a small harness: same prompt, every model, real latency, tokens and cost:
// same prompt, every model, real numbers
for (const test of TESTS) {
for (const model of MODELS) {
const res = await callModel(model, test.prompt, test.maxTokens);
const pass = test.grade ? (test.grade(res.text) ? "PASS" : "FAIL") : "--";
const usd = cost(model, res.inTok, res.outTok);
log(model, pass, res.ms, res.inTok, res.outTok, usd);
}
}The first receipt: Fable 5 found a live bug in my failover
The full three-model numbers are two sections down. Setting them up already paid for itself, because a fair test needs an answer key.
To score models on an audit of this repo I first had to know what is actually wrong with it. So on day one I put Fable 5 on the infrastructure behind this site: the failover worker, the GitHub Actions escape hatch, the Terraform. It came back with six findings I could verify line by line in the code. One of them was a production incident waiting for a date.
The monitor that guards this site checks the health of wojciech.io, the live domain. After a failover that domain points at the backup. So during any real outage the monitor would see a healthy backup, decide the outage was over, and flip DNS back to the broken primary. Five minutes later: failover again. For the whole length of the outage, my site would have see-sawed between working and broken on a five-minute clock.
The fix shipped the same day: the monitor now checks the primary origin directly before restoring DNS, and holds on the backup otherwise. This is the heart of it, from commit e734c2f in the public repo, so you can read every line instead of taking my word:
- } else if (healthy && !onPrimary) {
- await updateDns(env, CF_PAGES_HOSTNAME);
- console.log(`RESTORE -> CF Pages: ${CF_PAGES_HOSTNAME}`);
+ } else if (!onPrimary) {
+ // After a failover the apex serves the backup, so apex health says
+ // nothing about the primary. Restore only when the primary origin
+ // itself responds, otherwise DNS flip-flops every cron tick while
+ // the primary is down.
+ const primaryHealthy = await checkHealth(`https://${CF_PAGES_HOSTNAME}`);
+ if (primaryHealthy) {
+ await updateDns(env, CF_PAGES_HOSTNAME);
+ console.log(`RESTORE -> CF Pages: ${CF_PAGES_HOSTNAME}`);
+ } else {
+ console.log(`HOLD: serving backup, primary still unhealthy`);
+ }Fable 5 vs Opus 4.8 vs Sonnet 4.6: one answer key, the numbers
The runs ran in that sterile harness: identical clones of one commit, identical prompt, identical read-only tool limits, one run each for Fable 5, Opus 4.8 and Sonnet 4.6. The answer key was six bugs I had verified in the code by hand before any model started, weighted by severity, eleven points total. A point requires naming the mechanism, not just the file.
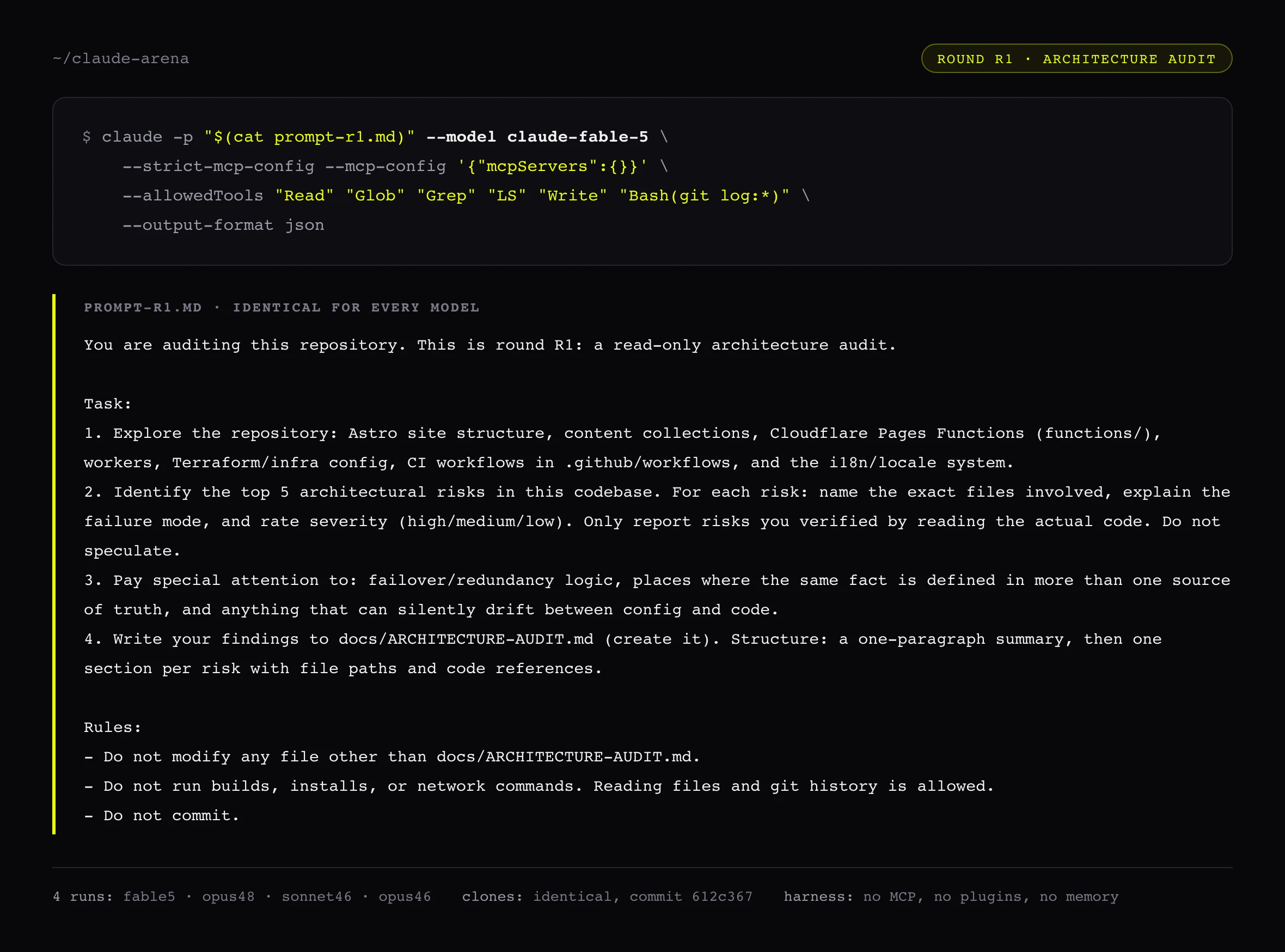
| Verified finding (weight) | Fable 5 | Opus 4.8 | Sonnet 4.6 |
|---|---|---|---|
| Failover flip-flop: health check probes the live domain, not the primary origin (3) | 3 | 3 | 0 |
| Worker and workflow disagree on what healthy means: worker passes a 404, workflow fails it (2) | 2 | 2 | 1 |
| Primary hostname hardcoded in three places (2) | 2 | 1.5 | 0 |
| DNS record outside Terraform, state backend local (2) | 1 | 1 | 0 |
| Env value pinned in public IaC (1) | 0.5 | 0.5 | 0 |
| Stale locale comment in _redirects (1) | 0 | 0 | 0 |
| Score out of 11 | 8.5 | 8.0 | 1 |
Each finding verified by me in the code before any model ran. Invented risks would have cost a point; nobody invented any.
| Metric | Fable 5 | Opus 4.8 | Sonnet 4.6 |
|---|---|---|---|
| Cost, USD | 2.57 | 0.86 | 0.76 |
| Wall time | 7m 18s | 3m 39s | 4m 37s |
| Agent turns | 32 | 22 | 40 |
| Cost per point found | $0.30 | $0.11 | $0.76 |
Cost per point is the row that matters: tokens are an input, found bugs are the output. Opus 4.8 found nearly as much as Fable for a third of the price per bug.
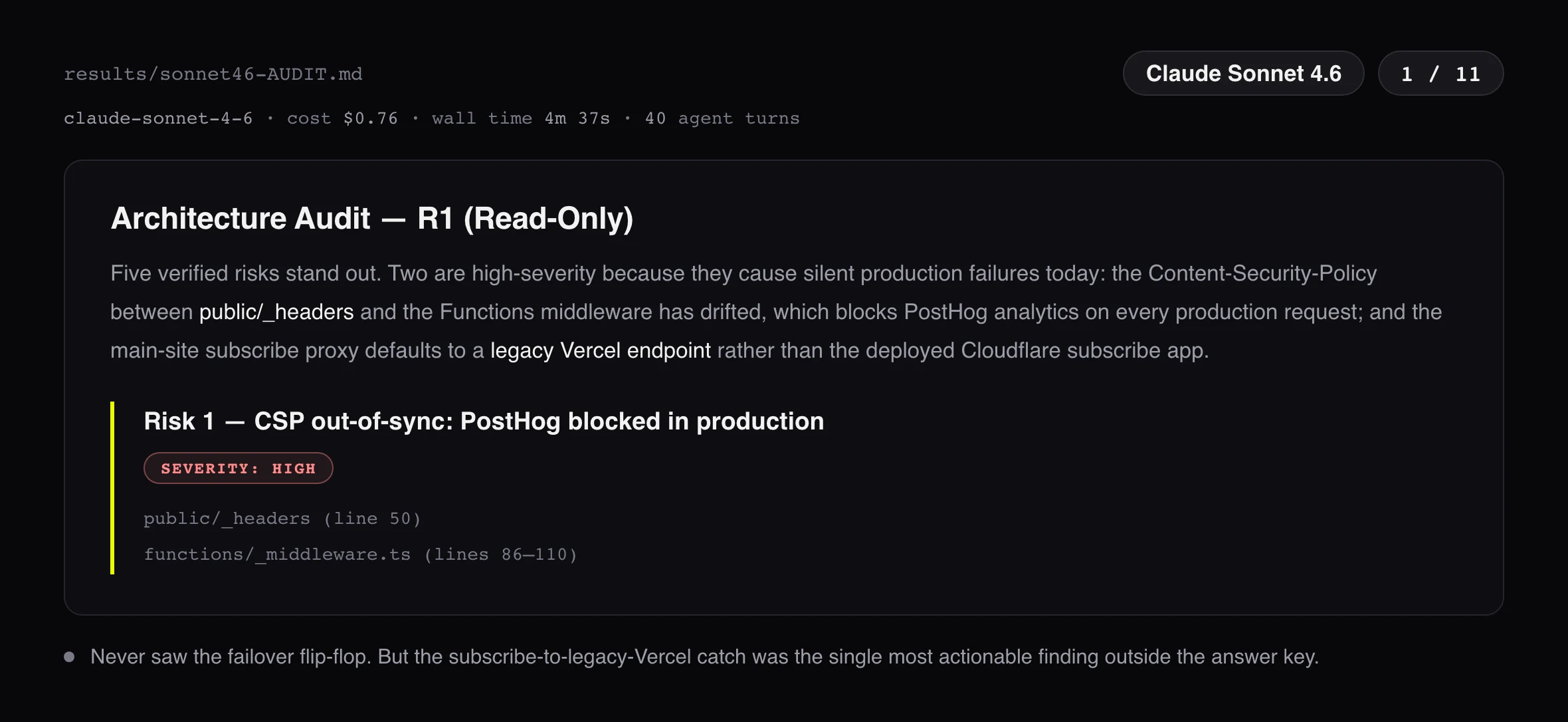
The verdict is less tidy than a leaderboard. Fable 5 found the most: 8.5 of 11, the only model to sweep the whole failover layer, the flip-flop and the two contradictory definitions of healthy and the hostname drift. But Opus 4.8 is the result that should stop you. It scored 8.0, half a point behind Fable, for $0.86 against $2.57. That is $0.11 per found bug against Fable’s $0.30: the model Fable costs double caught almost everything Fable did, at a third of the price per result. Sonnet 4.6 never saw the flip-flop at all, and still earned its run: it surfaced the single most actionable finding outside my answer key, a subscribe endpoint that silently falls back to a legacy Vercel app nothing maintains anymore.
One caveat on honesty about my own setup. On launch morning I only had API access to the older Opus 4.6, so the first version of this test scored that. It managed 4.5 of 11: it caught the flip-flop but went blind on the operational layer around it. I reran the whole thing on Opus 4.8, the current price reference Fable is measured against, and the jump from 4.5 to 8.0 on the exact same prompt is its own data point. The numbers above are all 4.8.
One more honest line the leaderboards never print. All three models flagged a finding my answer key had explicitly marked as a false positive: I believed my locale list was centralized in one file. They said it is declared independently in five places. I checked. They were right and my answer key was wrong. The benchmark audited the examiner.
What each model found outside the answer key
The score table only counts what was in my answer key. But every model also surfaced real, verified findings I had not listed. These are not bonus points. They are the reason you run three models instead of one.
| Model | Off-key finding (verified) | Impact |
|---|---|---|
| Fable 5 | Azure backup is dist-only, no API routes, no redirects, no security headers after failover | Partial outage: site renders, forms and headers vanish |
| Fable 5 | Two competing deploy pipelines with different env vars | Silent config drift between CI and Wrangler |
| Fable 5 | CSP in middleware and in Pages config already diverged (PostHog missing from one) | Analytics breakage on a subset of pages |
| Opus 4.8 | Azure failover backup rebuilds weekly from a bare build with no env vars | Failover can serve a week-stale, differently-built site |
| Opus 4.8 | Cloudflare account ID hard-coded across five deploy jobs | One ID copy-pasted five times, no single source to rotate |
| Sonnet 4.6 | Subscribe endpoint proxies to a legacy Vercel app nothing maintains | Subscribers silently drop into a dead pipeline |
| Sonnet 4.6 | crypto.ts duplicated across three apps, two copies byte-identical | Fix one, forget the other, ship a mismatch |
Every finding in this table is verified in the code. The subscribe endpoint was the single most actionable discovery of the whole benchmark, and it came from the model that scored lowest.
How the reports read, not just what they found
Numbers do not tell you what it is like to read a 2,000 word audit at 11 pm and decide whether to ship a fix. Here are the opening lines of each report, exactly as the models wrote them, with the bill attached.
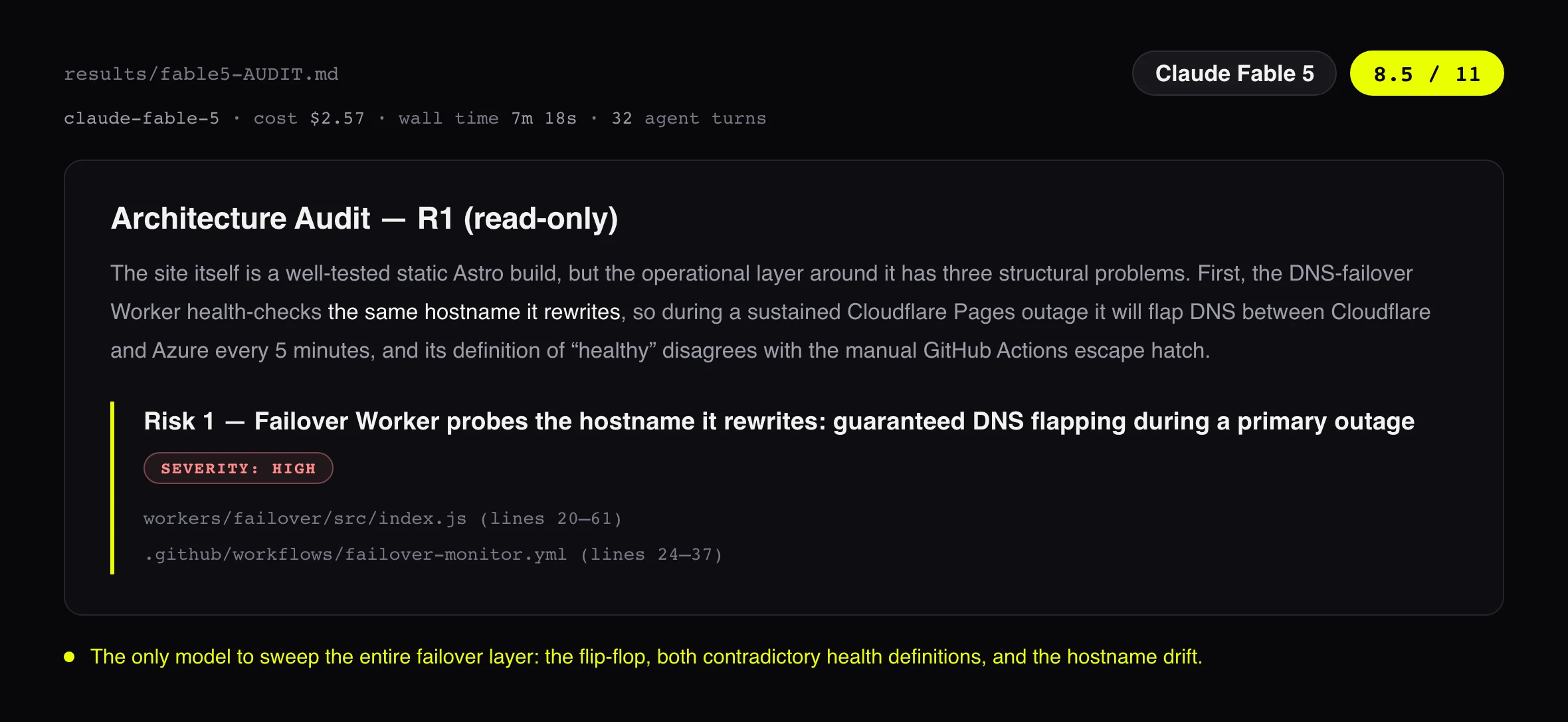
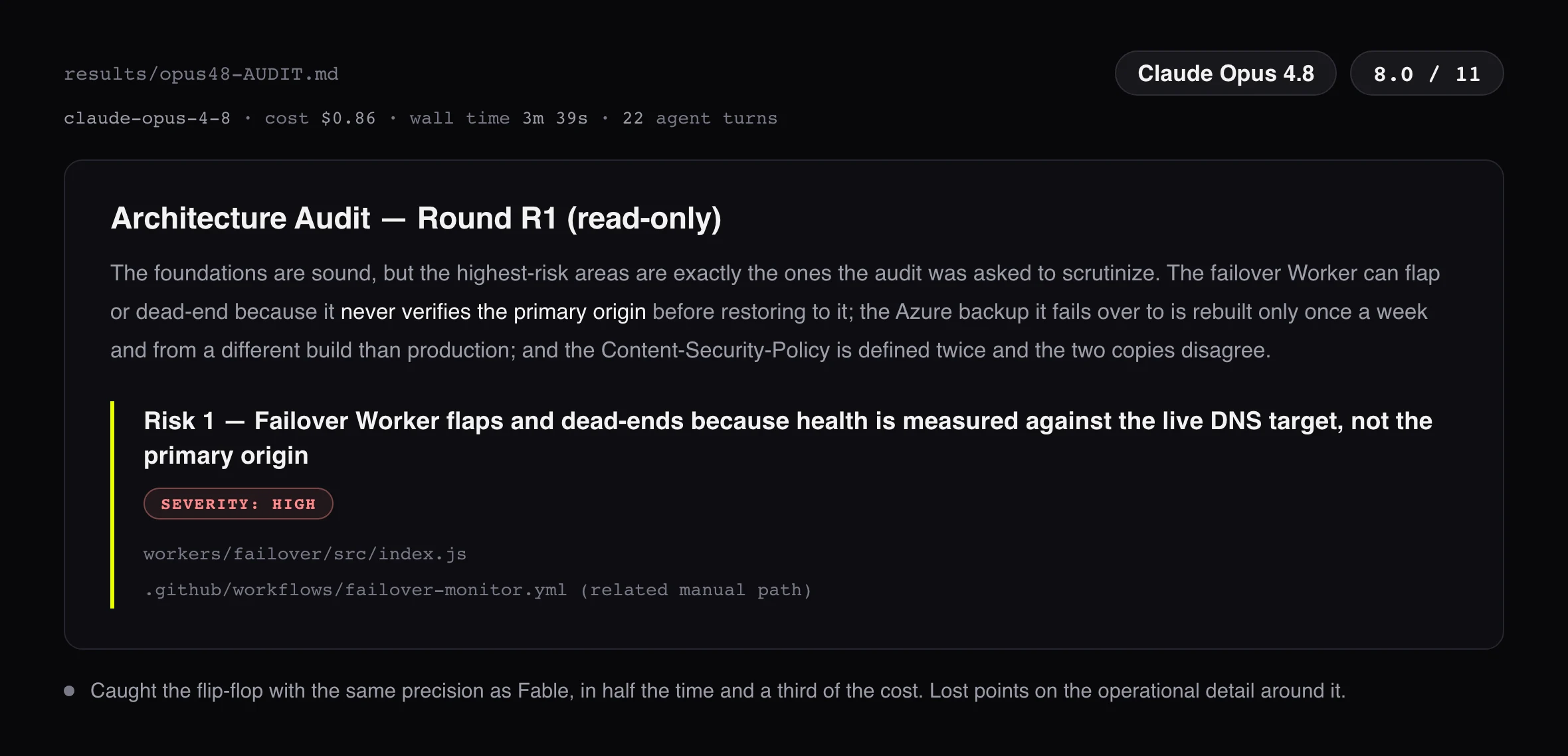
Reading them side by side is the fastest way to feel the gap. Beyond the first impression, I scored each report on four qualities, 1 to 5.
| Report quality | Fable 5 | Opus 4.8 | Sonnet 4.6 |
|---|---|---|---|
| File and line precision | 5 | 5 | 4 |
| Severity accuracy | 5 | 5 | 3 |
| Conciseness | 4 | 5 | 4 |
| Actionability of recommendations | 5 | 4 | 4 |
Subjective, my read. Fable and Opus 4.8 both quoted the code verbatim and got severity right; Opus was the tighter writer in fewer turns. Sonnet overcalled severity on one finding but gave the clearest fix steps.
Which model when, in one table:
| Situation | My pick | Why |
|---|---|---|
| Auditing a system the business depends on | Fable 5 | Swept the whole failover layer end to end; against a production outage the 2x price is noise |
| Daily agent work where budget matters | Opus 4.8 | Scored 8.0 to Fable's 8.5 for a third of the cost per bug; cheapest per point at $0.11 |
| A fast, cheap pass over concrete code issues | Sonnet 4.6 | Missed the scariest bug, but brought the single most actionable finding outside my answer key |
My split after one benchmark run. Your repo may vote differently.
Where Fable 5 actually earns its price for me
Not “smarter.” One thing: it holds the thread.
Every agent loop I run dies the same way. The model loses context at step N and starts inventing. My localization pipeline runs every block of an article through translate, restore and rebuild, times seven languages. The enrichment loop touches a CRM across many steps. The drift is the tax I pay, and today I pay it by re-running or by reading every line by hand, like I did four times this morning.
Fable’s headline claim is exactly this failure mode: hold context across millions of tokens, finish long agentic runs without losing the plot. The loudest proof point is Stripe running a codebase-wide migration across 50 million lines of Ruby in a single day, work Anthropic says would take a team two months by hand. The checkable version is the coding eval:
| Model | SWE-Bench Pro |
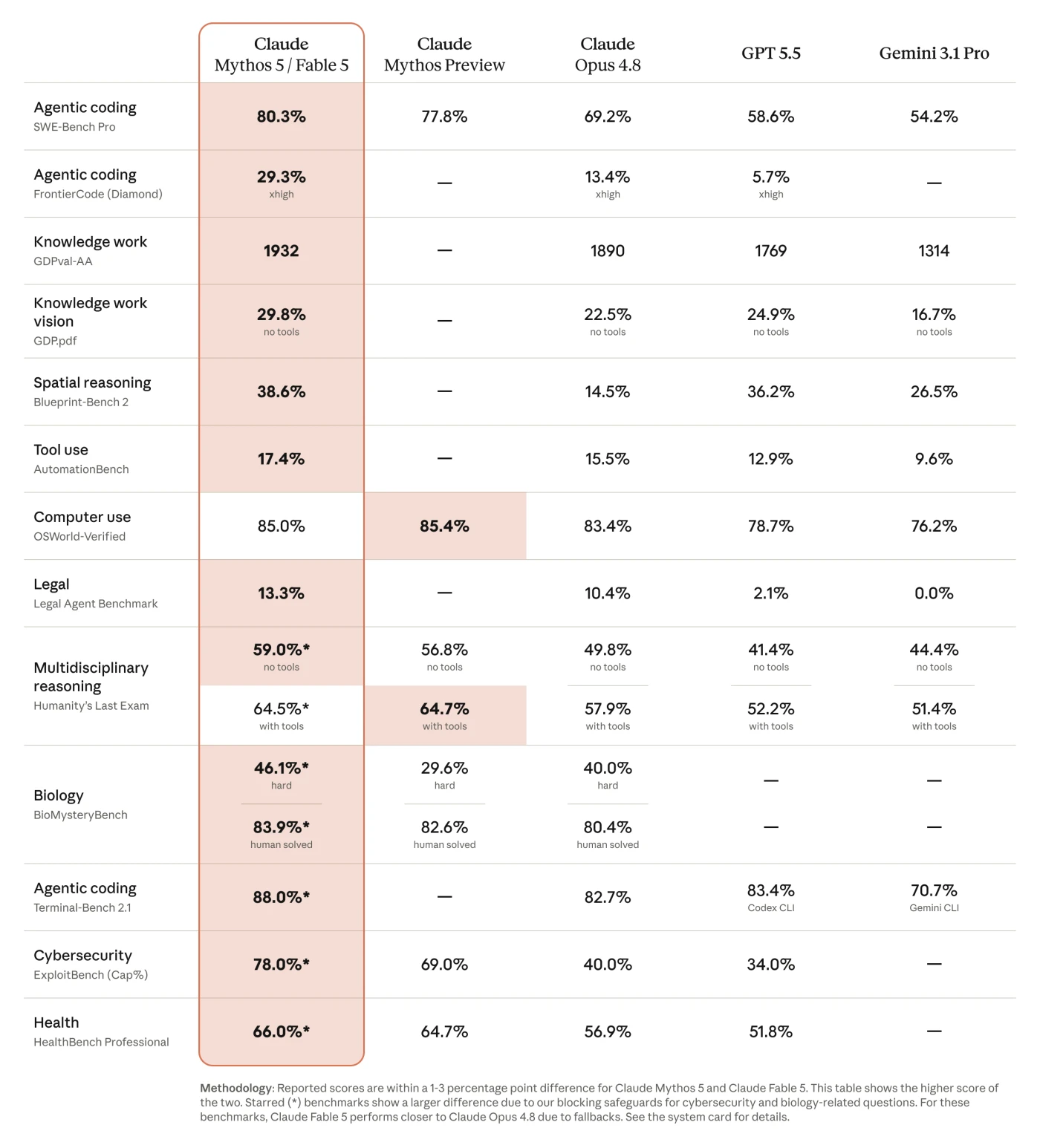
|---|---|
| Fable 5 | 80.3% |
| Opus 4.8 | 69.2% |
From the launch material, so treat it as a claim until your own workload confirms it. I am quoting it because long-horizon coding is exactly the work my repo throws at it, not because I reproduced it.
If that holds on my work, the win is not nicer output. It is one pass instead of three. That changes cost per result, which is the only number on the whole launch that touches my P&L.
Fable 5 pricing: 2x Opus 4.8, and the catch
When usage billing starts on June 23, Fable 5 and Mythos 5 both list at $10 per million input tokens and $50 per million output tokens. That is exactly double Opus 4.8, which sits at $5 and $25. These are published list prices, not my estimates.
| Info | Fable 5 / Mythos 5 | Opus 4.8 |
|---|---|---|
| Input tokens, per million | $10 | $5 |
| Output tokens, per million | $50 | $25 |
| Multiplier vs Opus | 2x | 1x |
| Free window ends | Jun 23 | n/a |
| Silent fallback to Opus 4.8 | <5% of sessions | n/a |
Published list prices. Fable 5 costs exactly twice as much as Opus 4.8. The frontier capability is what the premium buys.
The number that decides whether this is worth 2x is not on any price page: cost per finished result. A model that costs twice as much per token but finishes a long agentic run in half the steps can land cheaper per result. That is exactly what the harness above measures.
What the first 48 hours of Fable 5 produced
The launch was yesterday and the useful material is already piling up. This is the short list I actually opened and read to the end, not a link dump.
Worth your time since launch
Everything verified and opened by me on June 10. If it is on this list, I read or watched it.
5.5 hours of hands-on testing. His verdict: a slow, expensive beast that churns through everything. Matches my numbers.
Generally available in Copilot since launch day. The fastest way to try it inside an editor you already run.
Model IDs, the fallback mechanism, the new refusal signals. Read this before your agent loops meet the classifier.
The discourse angle: the most capable public model, days after Anthropic warned capability is getting dangerous.
What the new model gets right and very wrong, from the product side rather than the benchmark side.
120,000 characters of instructions, on GitHub within a day. Read what the model is told before it talks to you.
What to do with the free window
Fable 5 is free on Pro, Max, Team and seat-based Enterprise until June 22, then it moves to usage credits. That free window is two weeks to run it on real work before the meter starts.
- Test Fable 5 on your hardest real task during the free window
- Log which model answered when the fallback fires in agent loops
- Measure cost per finished result, not cost per token
- Re-run your own evals before trusting any launch-day number
- Repeat launch benchmarks as if you measured them
- Wire Mythos-class output into anything without reading the 30-day retention policy
- Assume the safeguards will not block a legitimate request
- Wait until June 23 and then complain it costs credits
If you are testing too, tell me what broke. That is the part no launch post will give you.
FAQ: Claude Fable 5 and Mythos 5
Is Claude Fable 5 the same model as Claude Mythos 5?
Yes. Anthropic confirms they share the same underlying model. The difference is the safeguards: Fable 5 is the general-release build that silently falls back to Opus 4.8 on flagged topics, Mythos 5 runs with some safeguards lifted and is restricted to vetted cyberdefense partners through Project Glasswing.
How much does Claude Fable 5 cost?
$10 per million input tokens and $50 per million output tokens, exactly twice Opus 4.8 ($5 and $25). It is free on Pro, Max, Team and seat-based Enterprise plans until June 22, 2026; usage billing starts June 23.
Is Claude Fable 5 better than Opus or Sonnet?
On my own benchmark, an audit of this site’s repo scored against a hand-verified answer key, Fable 5 took 8.5 of 11 points against 8.0 for Opus 4.8 and 1 for Sonnet 4.6, and it was the only model to sweep the whole failover layer. On cost per found bug, Opus 4.8 won by a wide margin, $0.11 against $0.30, scoring nearly as high for a third of the price. Anthropic’s own headline number is SWE-Bench Pro: 80.3% for Fable 5 against 69.2% for Opus 4.8. Treat all of it as input for your own eval, not a verdict.
Why did Opus 4.8 answer my Fable 5 request?
Fable 5 does not refuse flagged topics, it silently answers with Opus 4.8 instead. Anthropic says this happens in under 5% of sessions. If you run agent loops or evals, log which model replied, otherwise your numbers mix two models.
Sources and further reading
Primary sources
Anthropic's own pages plus the third-party evals cited on launch day.
Anthropic's full Fable 5 and Mythos 5 post.
Safety and capability test detail behind the claims.
The US government cyberdefense collaboration.
Earlier read on the cyber capability curve.
The coding eval Fable 5 is reported to top.
Independent work cited as backing a Mythos hypothesis.
If you want the operator context around this, I have written about running Claude Code as a GTM agent stack and the AI production stack I actually ship on. Same principle as here: the model is one layer, the system around it is the job.