
Claude Fable 5 pierwszego dnia znalazł u mnie żywego buga, więc zderzyłem go z Opusem i Sonnetem
Dałem Claude Fable 5, Opusowi 4.8 i Sonnetowi 4.6 do audytu repo własnej strony. Fable znalazł żywego buga w failoverze, Opus 4.8 był tańszy na wynik, Sonnet go przegapił. Wyniki, koszty, poprawka: wszystko publiczne.
GTM Architect & Growth Operator · Insights · 9 czerwca 2026
TL;DR · Najważniejsze wnioski
- Fable 5 i Mythos 5 to ten sam model. Jedyna różnica to zabezpieczenia: Fable przy oznaczonych tematach po cichu przełącza się na Opus 4.8, Mythos działa z częścią zabezpieczeń zdjętą dla zweryfikowanych partnerów.
- Dałem Fable 5, Opusowi 4.8 i Sonnetowi 4.6 do audytu repo tej strony, punktowane względem sześciu bugów, które najpierw zweryfikowałem ręcznie. Fable znalazł zdecydowanie najwięcej, w tym żywego buga produkcyjnego w moim failoverze DNS. Opus złapał tego samego głównego buga za połowę ceny. Sonnet go przegapił. Poprawka to publiczny commit, podlinkowany niżej.
- Kosztuje 2x tyle co Opus 4.8: 10 $ za tokeny wejściowe i 50 $ za wyjściowe, za milion. Opłaca się tylko wtedy, gdy kończy zadanie w mniejszej liczbie kroków. Liczy się koszt wyniku, nie koszt tokena.
- Haczyk, którego nikt nie pokazuje na slajdzie: cichy fallback oznacza, że w jednej sesji mogą odpowiadać dwa różne modele. Jeśli puszczasz pętle agentowe, loguj, który odpowiedział, inaczej twoje liczby kłamią.
Anthropic wypuścił dziś, 9 czerwca 2026, dwa modele frontier: Claude Fable 5 i Claude Mythos 5. Jeden jest dla wszystkich. Drugi siedzi za programem zaufanego dostępu. Pod spodem to ten sam model.
Wpis premierowy to benchmark na benchmarku. Nie zamierzam ich streszczać. Na Claude prowadzę biznes, nie leaderboard, i obchodzi mnie jedno pytanie: co mocniejszy model robi z systemami, które już dziś u mnie działają. Ta strona w ośmiu językach. Pipeline treści. Pętle agentowe, które dotykają CRM-u. Oto ta odpowiedź, na mojej własnej robocie, z dowodami, które możesz sklonować i odpalić u siebie.
| Model | Wynik / 11 | Koszt / znaleziony bug | W jednym zdaniu |
|---|---|---|---|
| Claude Fable 5 | 8.5 | $0.30 | Znalazł najwięcej i jako jedyny w pełni złapał żywego buga failovera |
| Claude Opus 4.8 | 8.0 | $0.11 | Złapał prawie tyle samo za jedną trzecią ceny na buga: najtańszy na wynik |
| Claude Sonnet 4.6 | 1 | $0.76 | Przegapił najgroźniejszego, ale przyniósł realnego buga spoza mojego klucza |
Cały benchmark w jednej tabeli. Punktacja per znalezisko, koszty i dokładna metoda są niżej.
Fable 5 i Mythos 5: dwa modele, jeden mózg
Nazwa zdradza wszystko. Anthropic tłumaczy, że fable pochodzi od łacińskiego fabula, „to, co opowiedziane”, blisko greckiego mythos. Ten sam rdzeń, dwie maski. Różnica nie leży w możliwościach. Leży w tym, co modelowi wolno.

Claude Fable 5 jest od dziś w API i w każdym planie. Zabezpieczenia włączone. Gdy żądanie trafi w oznaczony temat, model nie odmawia, tylko po cichu odpowiada jako Opus 4.8. Według Anthropic dzieje się tak w mniej niż 5% sesji.
Claude Mythos 5 to ten sam model pod spodem, część zabezpieczeń zdjęta. Dostęp tylko dla zweryfikowanych zespołów cyberobrony przez Project Glasswing, program biologiczny ma dojść później. Anthropic nazywa go najmocniejszym modelem cyber, jaki zbudował.
To jedyny detal tej premiery, który dotyka każdego, kto buduje na API. Cichy fallback to lepszy UX niż twarda odmowa. Oznacza też, że w jednej sesji mogą odpowiadać dwa różne modele. Jeśli puszczasz evale albo pętle agentowe, musisz logować, który odpowiedział, inaczej twoje liczby po cichu mieszają dwa modele.
Co już dziś działa tu na Claude
Zanim powiem, co Fable zmienia, pokażę, w czym ma coś zmieniać. Ta strona to nie wizytówka. To system, a Claude jest w nim elementem nośnym.
Działa na Astro i Cloudflare, serverless, nie ma czym się opiekować. Strona wychodzi w ośmiu językach przez pipeline na DeepL, który zbudowałem, z warstwą ochrony marek, żeby tłumacz nigdy nie zrobił z „Opusa” rzeczownika pospolitego. Ten pipeline wyprodukował 89 zlokalizowanych wersji artykułów w siedmiu językach i każda z nich siedzi w kolekcjach treści tego repo, gdzie możesz je policzyć. Warstwa odkrywania, llms.txt, jest na bieżąco, żeby modele mogły znaleźć tę robotę. Nic z tego nie jest demem. Wszystko siedzi w repo za tą stroną.
| Metryka | Wartość | Info |
|---|---|---|
| Języki | 8 | EN plus 7, z jednej edycji źródła |
| Zbudowanych stron | 180 | każdy deploy przechodzi CI |
| Testów | 560 | schema, linki, build |
| Serwerów | 0 | Astro na Cloudflare, serverless |
Ta strona, tak jak buduje się dzisiaj. Sklonuj repo i dostaniesz te same liczby.
Jedna prawdziwa robota, osiem języków, jedna sesja
Porównanie cen, które znajdziesz niżej na tej stronie: oto jak powstało, dzisiaj, za jednym posiedzeniem. Taką robotę mam na myśli.
- Jedna edycja, po angielsku. Napisałem porównanie cen raz, w języku kanonicznym, jako jedyne źródło prawdy.
- Chirurgiczna wstawka, nie re-tłumaczenie. Skrypt przetłumaczył tylko nowy blok na siedem języków i wpiął go pod właściwy nagłówek, nie ruszając żadnego z ręcznie poprawionych tłumaczeń.
- Część, której nie pokaże żaden wpis premierowy. Zajęło to cztery podejścia. DeepL odczytał “credits” jako napisy końcowe filmu, “model card” jako kartę postaci z RPG, a “$5 wejście, $25 wyjście” jako ceny kupna i sprzedaży. Przeczytałem każdą linię i poprawiłem sens. Model zrobił wolumen, osąd należał do mnie.
- Na produkcji. Build zielony, 560 testów, push na maina. Osiem języków spójnych. Jedna sesja.
Tłumacz ogarnął osiem języków w kilka sekund. Cztery razy pomylił też sens. Żadna z tych rzeczy nie jest niespodzianką i obie są częścią roboty. Mocniejszy model przesuwa tę granicę: mniej podejść, mniej mojego osądu spalanego na sprzątanie.
Trzy fronty, które Claude Fable 5 musi przetrwać: czat, agenci, kod
Ten sam model, trzy zupełnie różne roboty. Szybki osąd w oknie czatu. Długi, wielokrokowy przebieg w agencie cowork. Kod w tym repo. Na każdym froncie psuje się inaczej, a model frontier jest wart swojej ceny tylko wtedy, gdy trzyma się na wszystkich trzech.
Jedno prawdziwe zadanie na front
Ten sam model musi być dobry w trzech różnych robotach, a każda psuje się inaczej.
Oceń inbounda względem mojego ICP i napisz dwulinijkowy opener. Testuje osąd i zwięzłość w jednej turze.
Weź pięć URL-i z LinkedIna, wzbogać każdy, przygotuj spersonalizowaną sekwencję, zapisz do CRM-u. Testuje długą robotę agentową bez dryfu przez wiele kroków.
Zrefaktoruj kolekcję treści w całym repo i utrzymaj zielony build. Testuje kontekst wielu plików trzymany do końca, nie tylko przy pierwszej edycji.
Front kodu ma paragony, bo działa tutaj i liczby są publiczne. Żeby uczciwie porównać modele, kazałem Claude’owi zbudować mały harness: ten sam prompt, każdy model, realna latencja, tokeny i koszt:
// ten sam prompt, każdy model, prawdziwe liczby
for (const test of TESTS) {
for (const model of MODELS) {
const res = await callModel(model, test.prompt, test.maxTokens);
const pass = test.grade ? (test.grade(res.text) ? "PASS" : "FAIL") : "--";
const usd = cost(model, res.inTok, res.outTok);
log(model, pass, res.ms, res.inTok, res.outTok, usd);
}
}Pierwszy paragon: Fable 5 znalazł żywego buga w moim failoverze
Pełne liczby trzech modeli są dwie sekcje niżej. Samo ich przygotowanie już się zwróciło, bo uczciwy test potrzebuje klucza odpowiedzi.
Żeby punktować modele za audyt tego repo, najpierw musiałem wiedzieć, co w nim naprawdę jest nie tak. Więc pierwszego dnia posadziłem Fable 5 nad infrastrukturą tej strony: worker failovera, ręczna zapadnia w GitHub Actions, Terraform. Wrócił z sześcioma znaleziskami, które zweryfikowałem w kodzie linia po linii. Jedno z nich to awaria produkcyjna czekająca na swój termin.
Monitor, który pilnuje tej strony, sprawdza zdrowie wojciech.io, czyli żywej domeny. Po failoverze ta domena wskazuje na backup. Podczas prawdziwej awarii monitor widziałby więc zdrowy backup, uznałby, że awaria minęła, i przepiąłby DNS z powrotem na zepsuty primary. Pięć minut później: znowu failover. Przez całą awarię moja strona huśtałaby się między działającą a zepsutą w rytmie pięciu minut.
Poprawka weszła tego samego dnia: monitor sprawdza teraz bezpośrednio origin primary, zanim przywróci DNS, a w innym wypadku zostaje na backupie. To jej serce, z commita e734c2f w publicznym repo, więc możesz przeczytać każdą linię zamiast wierzyć mi na słowo:
- } else if (healthy && !onPrimary) {
- await updateDns(env, CF_PAGES_HOSTNAME);
- console.log(`RESTORE -> CF Pages: ${CF_PAGES_HOSTNAME}`);
+ } else if (!onPrimary) {
+ // After a failover the apex serves the backup, so apex health says
+ // nothing about the primary. Restore only when the primary origin
+ // itself responds, otherwise DNS flip-flops every cron tick while
+ // the primary is down.
+ const primaryHealthy = await checkHealth(`https://${CF_PAGES_HOSTNAME}`);
+ if (primaryHealthy) {
+ await updateDns(env, CF_PAGES_HOSTNAME);
+ console.log(`RESTORE -> CF Pages: ${CF_PAGES_HOSTNAME}`);
+ } else {
+ console.log(`HOLD: serving backup, primary still unhealthy`);
+ }Fable 5 vs Opus 4.8 vs Sonnet 4.6: jeden klucz odpowiedzi, liczby
Przebiegi poszły w tym sterylnym harnessie: identyczne klony jednego commita, identyczny prompt, identyczne limity narzędzi tylko do odczytu, po jednym przebiegu dla Fable 5, Opus 4.8 i Sonnet 4.6. Kluczem odpowiedzi było sześć bugów, które zweryfikowałem w kodzie ręcznie, zanim jakikolwiek model wystartował, ważonych po severity, jedenaście punktów łącznie. Punkt wymaga nazwania mechanizmu, nie samego pliku.
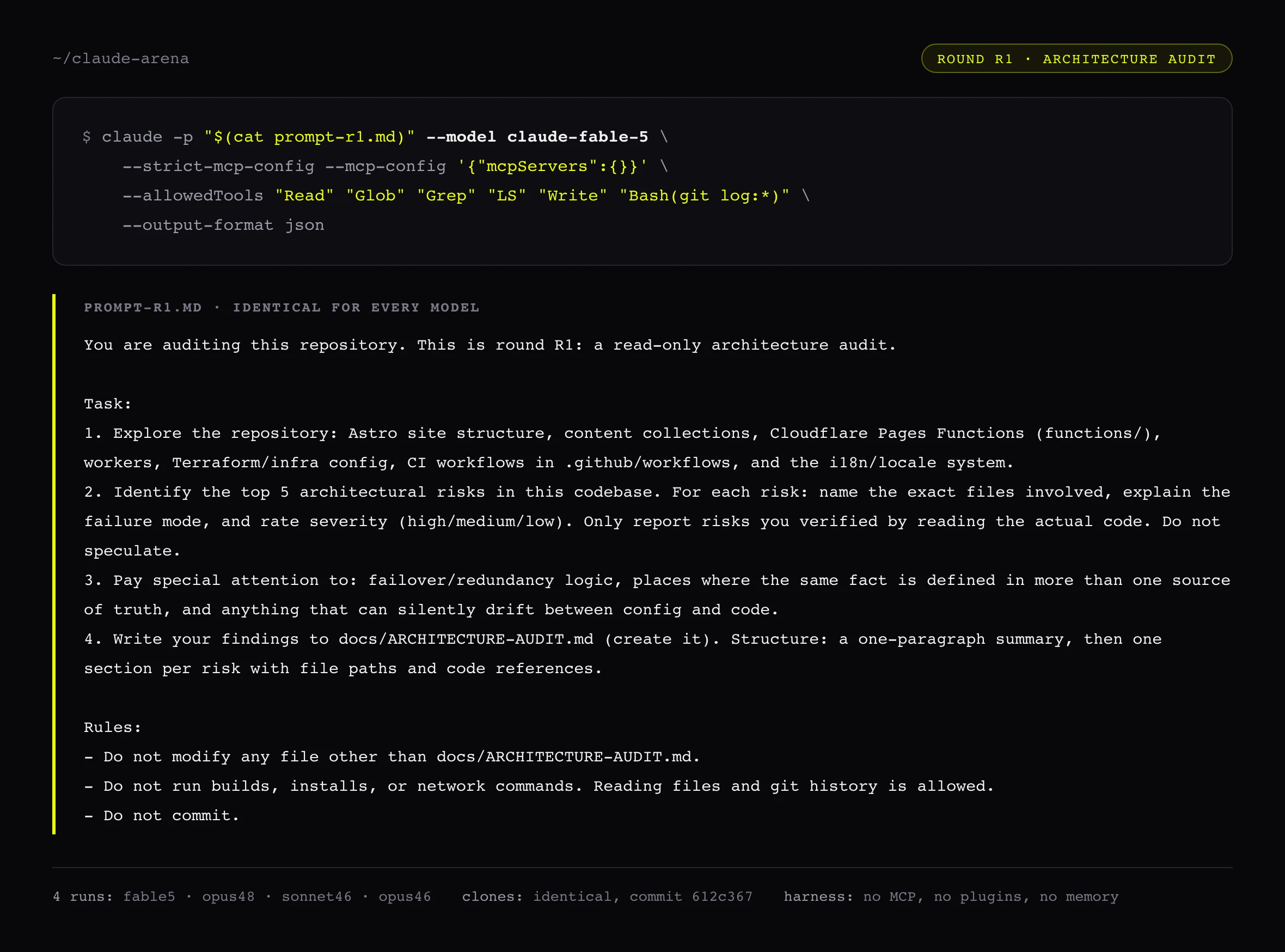
| Zweryfikowane znalezisko (waga) | Fable 5 | Opus 4.8 | Sonnet 4.6 |
|---|---|---|---|
| Flip-flop failovera: health check odpytuje żywą domenę, nie origin primary (3) | 3 | 3 | 0 |
| Worker i workflow nie zgadzają się, co znaczy zdrowy: worker przepuszcza 404, workflow go oblewa (2) | 2 | 2 | 1 |
| Hostname primary zahardkodowany w trzech miejscach (2) | 2 | 1.5 | 0 |
| Rekord DNS poza Terraformem, backend stanu lokalny (2) | 1 | 1 | 0 |
| Wartość env wpisana na sztywno w publicznym IaC (1) | 0.5 | 0.5 | 0 |
| Stały komentarz o locale w _redirects (1) | 0 | 0 | 0 |
| Wynik na 11 | 8.5 | 8.0 | 1 |
Każde znalezisko zweryfikowałem w kodzie, zanim którykolwiek model ruszył. Wymyślone ryzyko kosztowałoby punkt; nikt żadnego nie wymyślił.
| Metryka | Fable 5 | Opus 4.8 | Sonnet 4.6 |
|---|---|---|---|
| Koszt, USD | 2.57 | 0.86 | 0.76 |
| Czas zegarowy | 7m 18s | 3m 39s | 4m 37s |
| Tury agenta | 32 | 22 | 40 |
| Koszt znalezionego punktu | $0.30 | $0.11 | $0.76 |
Koszt na punkt to wiersz, który się liczy: tokeny są wejściem, znalezione bugi wyjściem. Opus 4.8 znalazł prawie tyle co Fable za jedną trzecią ceny na buga.
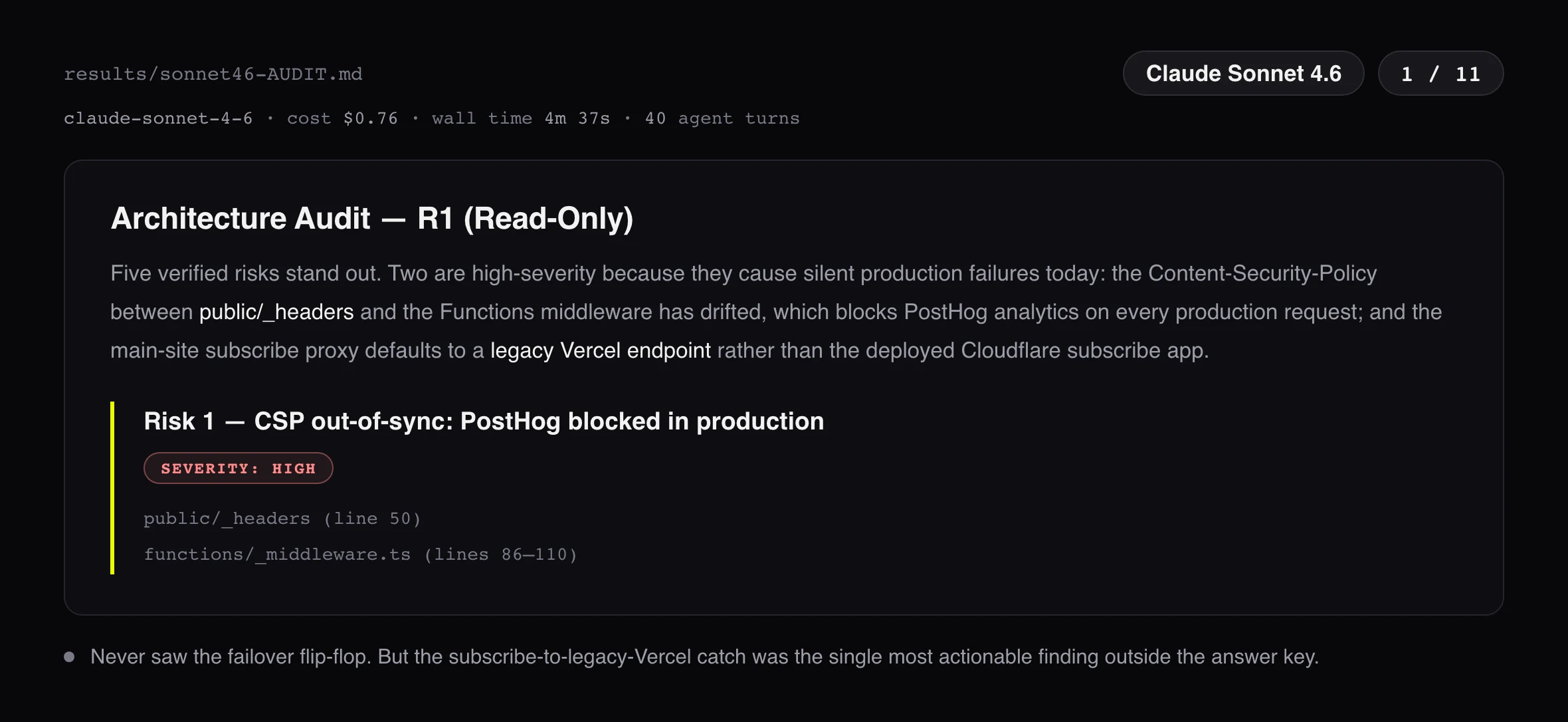
Werdykt jest mniej elegancki niż leaderboard. Fable 5 znalazł najwięcej: 8.5 na 11, jako jedyny zgarnął całą warstwę failovera, flip-flop i dwie sprzeczne definicje zdrowia i dryf hostname. Ale to Opus 4.8 jest wynikiem, przy którym warto się zatrzymać. Dostał 8.0, pół punktu za Fable, za 0,86 $ wobec 2,57 $. To 0,11 $ na znalezionego buga wobec 0,30 $ u Fable: model, od którego Fable jest dwa razy droższy, złapał prawie wszystko to co Fable, za jedną trzecią ceny na wynik. Sonnet 4.6 w ogóle nie zobaczył flip-flopa, a i tak zarobił na swój przebieg: przyniósł najbardziej akcjonalne znalezisko spoza mojego klucza, endpoint zapisu na newsletter, który po cichu spada na starą appkę na Vercelu, której nikt już nie utrzymuje.
Jedno uczciwe zastrzeżenie o moim własnym setupie. Rano w dniu premiery miałem dostęp API tylko do starszego Opus 4.6, więc pierwsza wersja tego testu punktowała właśnie jego. Wyszło 4.5 na 11: złapał flip-flop, ale był ślepy na warstwę operacyjną wokół. Powtórzyłem cały test na Opus 4.8, aktualnym punkcie odniesienia ceny, względem którego mierzony jest Fable, a skok z 4.5 do 8.0 na dokładnie tym samym prompcie to osobny datapoint. Liczby powyżej są w całości z 4.8.
Jeszcze jedna uczciwa linijka, której leaderboardy nigdy nie drukują. Wszystkie trzy modele zgłosiły znalezisko, które mój klucz odpowiedzi jawnie oznaczał jako fałszywy alarm: byłem przekonany, że lista locale jest scentralizowana w jednym pliku. One powiedziały, że jest deklarowana niezależnie w pięciu miejscach. Sprawdziłem. Miały rację, a mój klucz się mylił. Benchmark zaudytował egzaminatora.
Co każdy model znalazł poza kluczem odpowiedzi
Tabela wyników liczy tylko to, co było w moim kluczu. Ale każdy model przyniósł też prawdziwe, zweryfikowane znaleziska, których nie wpisałem. To nie punkty bonusowe. To powód, dla którego puszczasz trzy modele zamiast jednego.
| Model | Znalezisko spoza klucza (zweryfikowane) | Wpływ |
|---|---|---|
| Fable 5 | Backup Azure to sam dist, brak route'ów API, redirectów i nagłówków bezpieczeństwa po failoverze | Częściowa awaria: strona się renderuje, formularze i nagłówki znikają |
| Fable 5 | Dwa konkurencyjne pipeline'y deploy z różnymi zmiennymi env | Cichy dryf konfiguracji między CI a Wranglerem |
| Fable 5 | CSP w middleware i w konfiguracji Pages już rozjechane (PostHog brakuje w jednej) | Analityka nie działa na części stron |
| Opus 4.8 | Backup failovera na Azure odbudowuje się raz w tygodniu z gołego builda bez zmiennych env | Failover może serwować tydzień stary, inaczej zbudowany serwis |
| Opus 4.8 | ID konta Cloudflare wpisane na sztywno w pięciu jobach deployu | Jedno ID skopiowane pięć razy, brak jednego źródła do rotacji |
| Sonnet 4.6 | Endpoint zapisu proxuje na starą appkę na Vercelu, której nikt nie utrzymuje | Subskrybenci lądują w martwym pipeline |
| Sonnet 4.6 | crypto.ts zduplikowany w trzech appkach, dwie kopie bajt w bajt identyczne | Napraw jedną, zapomnij o drugiej, wyślij niespójność |
Każde znalezisko w tej tabeli jest zweryfikowane w kodzie. Endpoint zapisu to najbardziej akcjonalne odkrycie całego benchmarku, a przyszło od modelu z najniższym wynikiem.
Jak się czytają raporty, nie tylko co znalazły
Liczby nie mówią, jak to jest czytać dwutysięczny raport o 23:00 i decydować, czy puszczać fixa. Oto pierwsze linie każdego raportu, dokładnie tak, jak modele je napisały, z rachunkiem obok.
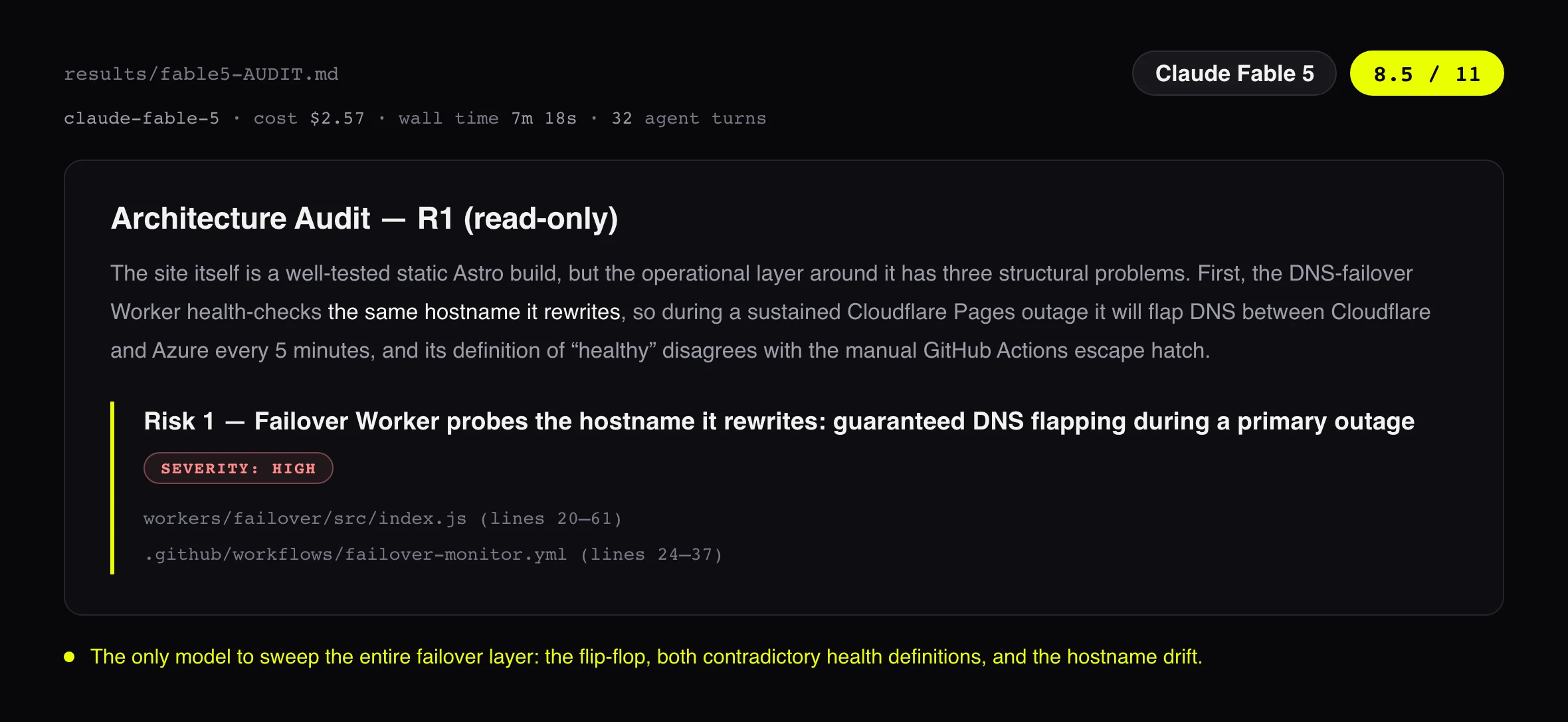
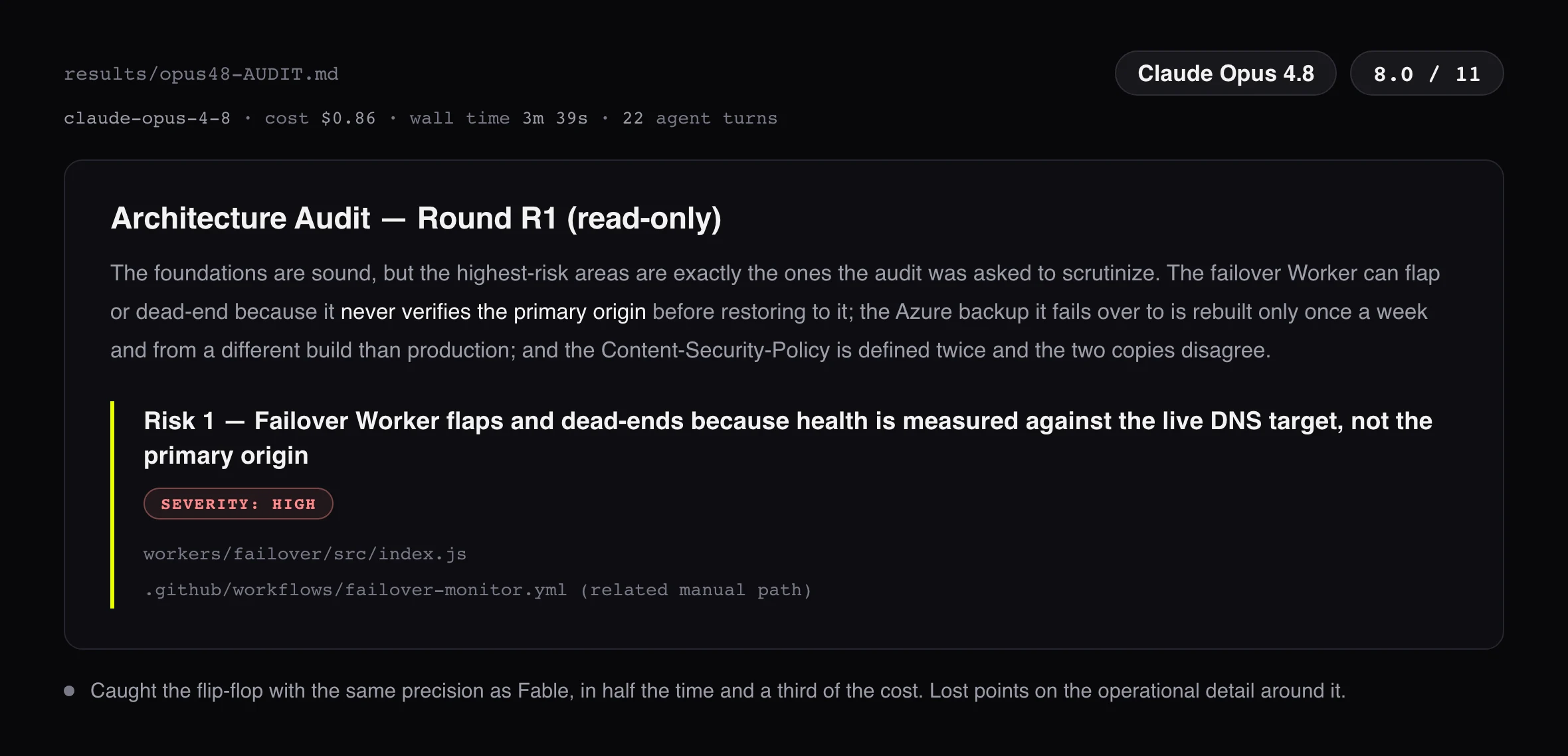
Czytanie ich obok siebie to najszybszy sposób, żeby poczuć różnicę. Poza pierwszym wrażeniem oceniłem każdy raport na czterech osiach, 1 do 5.
| Jakość raportu | Fable 5 | Opus 4.8 | Sonnet 4.6 |
|---|---|---|---|
| Precyzja plików i linii | 5 | 5 | 4 |
| Trafność severity | 5 | 5 | 3 |
| Zwięzłość | 4 | 5 | 4 |
| Wykonalność rekomendacji | 5 | 4 | 4 |
Subiektywna ocena, moja lektura. Fable i Opus 4.8 oba cytowały kod dosłownie i trafiły severity; Opus pisał zwięźlej, w mniejszej liczbie tur. Sonnet przeszacował jedno severity, ale dał najczystsze kroki naprawcze.
Kiedy który model, w jednej tabeli:
| Sytuacja | Mój wybór | Dlaczego |
|---|---|---|
| Audyt systemu, od którego zależy biznes | Fable 5 | Zebrał całą warstwę failovera od początku do końca; przy awarii produkcyjnej różnica 2x w cenie nie gra roli |
| Codzienna robota agentowa, budżet się liczy | Opus 4.8 | Dostał 8.0 przy 8.5 Fable za jedną trzecią ceny na buga; najtańszy na punkt: 0,11 $ |
| Szybkie, tanie przejście po koderskich konkretach | Sonnet 4.6 | Najgroźniejszego buga nie zobaczył, ale przyniósł najbardziej akcjonalne znalezisko spoza klucza |
Mój podział po jednym przebiegu benchmarku. Na twoim repo może wyjść inaczej.
Gdzie Fable 5 naprawdę zarabia u mnie na swoją cenę
Nie „mądrzejszy”. Jedna rzecz: trzyma wątek.
Każda pętla agentowa, którą puszczam, umiera tak samo. Model gubi kontekst na kroku N i zaczyna zmyślać. Mój pipeline lokalizacji przepuszcza każdy blok artykułu przez tłumaczenie, odtworzenie i ponowne złożenie, razy siedem języków. Pętla wzbogacania dotyka CRM-u przez wiele kroków. Dryf to podatek, który płacę, a dziś płacę go ponownymi przebiegami albo czytaniem każdej linii ręcznie, jak dziś rano, cztery razy.
Główna obietnica Fable’a celuje dokładnie w ten tryb awarii: trzymać kontekst przez miliony tokenów, kończyć długie przebiegi agentowe bez gubienia wątku. Najgłośniejszy dowód to Stripe, który w jeden dzień przeprowadził migrację 50 milionów linii Ruby w całym kodzie, robota, która według Anthropic zajęłaby zespołowi dwa miesiące ręcznie. Wersja do sprawdzenia to eval kodowania:
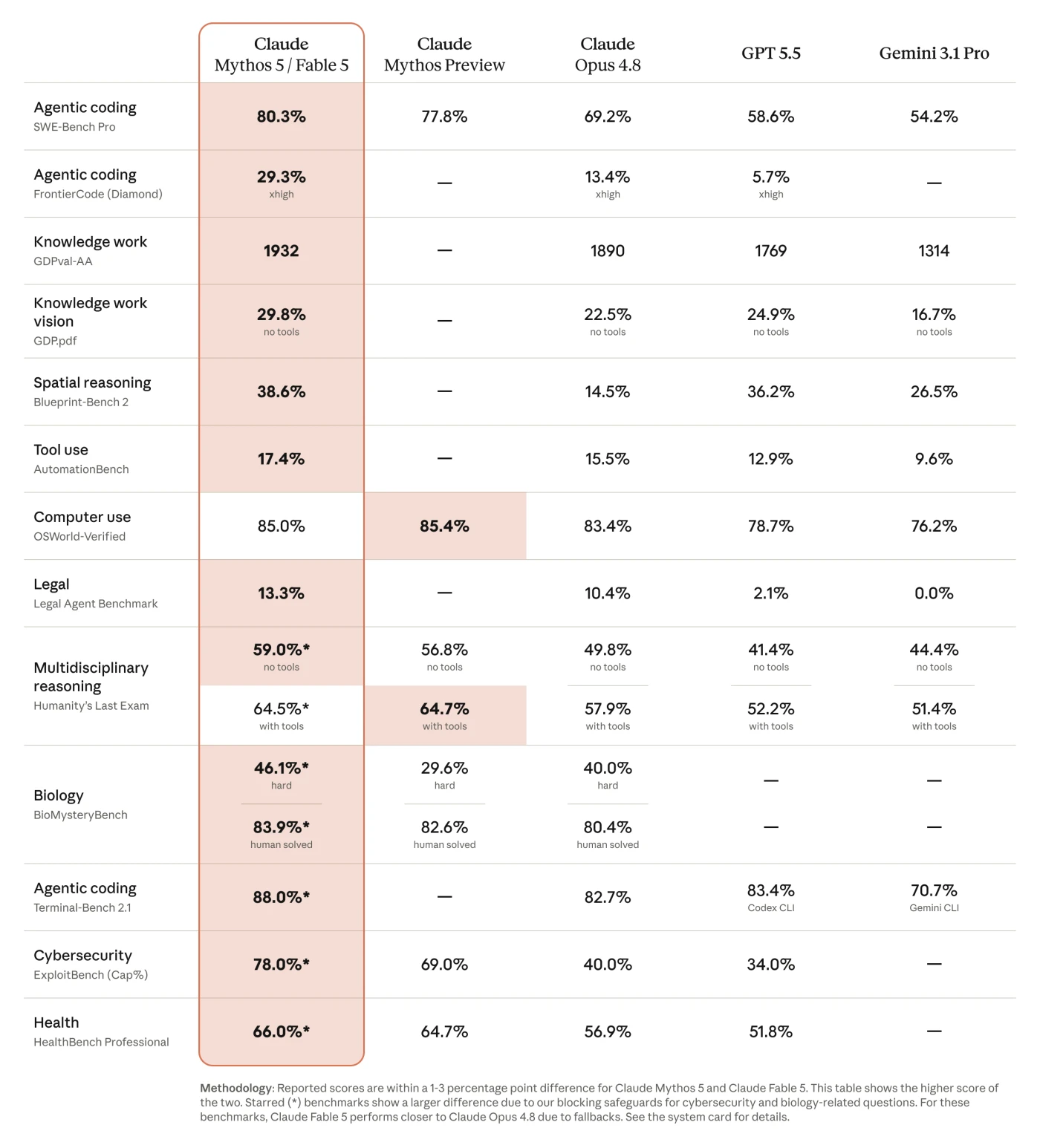
| Model | SWE-Bench Pro |
|---|---|
| Fable 5 | 80,3% |
| Opus 4.8 | 69,2% |
Z materiałów premierowych, więc traktuj to jako deklarację, dopóki twój własny workload jej nie potwierdzi. Cytuję ją, bo długie kodowanie to dokładnie ta robota, którą rzuca w model moje repo, a nie dlatego, że ją odtworzyłem.
Jeśli to się potwierdzi na mojej robocie, wygrana to nie ładniejszy output. To jeden przebieg zamiast trzech. A to zmienia koszt wyniku, jedyną liczbę z całej premiery, która dotyka mojego P&L.
Cennik Fable 5: 2x Opus 4.8, i haczyk
Gdy 23 czerwca ruszy rozliczanie za użycie, Fable 5 i Mythos 5 będą kosztować po 10 $ za milion tokenów wejściowych i 50 $ za milion wyjściowych. To dokładnie dwa razy tyle co Opus 4.8, który stoi na 5 $ i 25 $. To opublikowane ceny katalogowe, nie moje szacunki.
| Info | Fable 5 / Mythos 5 | Opus 4.8 |
|---|---|---|
| Tokeny wejściowe, za milion | $10 | $5 |
| Tokeny wyjściowe, za milion | $50 | $25 |
| Mnożnik vs Opus | 2x | 1x |
| Koniec darmowego okna | 23 cze | n/d |
| Cichy fallback do Opus 4.8 | <5% sesji | n/d |
Opublikowane ceny katalogowe. Fable 5 kosztuje dokładnie dwa razy tyle co Opus 4.8. Premia kupuje możliwości frontier.
Liczby, która rozstrzyga, czy to jest warte 2x, nie znajdziesz na żadnym cenniku: koszt skończonego wyniku. Model dwa razy droższy za token, który kończy długi przebieg agentowy w połowie kroków, może wyjść taniej na wynik. I dokładnie to ma mierzyć harness wyżej.
Co urodziło pierwsze 48 godzin Fable 5
Premiera była wczoraj, a użytecznego materiału już przybywa. To jest krótka lista rzeczy, które naprawdę otworzyłem i doczytałem do końca, nie wysypisko linków.
Warte twojego czasu od premiery
Wszystko zweryfikowane i otwarte przeze mnie 10 czerwca. Jeśli coś jest na tej liście, to to przeczytałem.
5,5 godziny testów na żywym kodzie. Werdykt: powolna, droga bestia, która przerabia wszystko. Zgadza się z moimi liczbami.
Ogólnodostępny w Copilocie od dnia premiery. Najszybsza droga, żeby spróbować go w edytorze, który już masz.
Identyfikatory modeli, mechanizm fallbacku, nowe sygnały odmowy. Przeczytaj, zanim twoje pętle agentowe spotkają klasyfikator.
Wątek dyskursu: najmocniejszy publiczny model kilka dni po tym, jak Anthropic ostrzegał, że możliwości robią się niebezpieczne.
Co nowy model robi dobrze, a co bardzo źle, od strony produktu, nie benchmarku.
120 000 znaków instrukcji, na GitHubie w dobę po premierze. Przeczytaj, co model dostaje, zanim odezwie się do ciebie.
Co zrobić z darmowym oknem
Fable 5 jest darmowy w planach Pro, Max, Team i Enterprise na stanowiska do 22 czerwca, potem przechodzi na kredyty za użycie. To darmowe okno to dwa tygodnie na przetestowanie go na prawdziwej robocie, zanim ruszy licznik.
- Przetestuj Fable 5 na swoim najtrudniejszym prawdziwym zadaniu w darmowym oknie
- Loguj, który model odpowiedział, gdy w pętlach agentowych odpali się fallback
- Mierz koszt skończonego wyniku, nie koszt tokena
- Przepuść własne evale, zanim uwierzysz w jakąkolwiek liczbę z dnia premiery
- Powtarzać benchmarków z premiery, jakbyś sam je zmierzył
- Wpinać outputu klasy Mythos w cokolwiek bez przeczytania polityki 30-dniowej retencji
- Zakładać, że zabezpieczenia nie zablokują uzasadnionego żądania
- Czekać do 23 czerwca i potem narzekać, że kosztuje kredyty
Jeśli też testujesz, napisz mi, co się u ciebie wyłożyło. Tego żaden wpis premierowy ci nie da.
FAQ: Claude Fable 5 i Mythos 5
Czy Claude Fable 5 to ten sam model co Claude Mythos 5?
Tak. Anthropic potwierdza, że pod spodem to ten sam model. Różnica to zabezpieczenia: Fable 5 to wersja ogólnodostępna, która przy oznaczonych tematach po cichu przełącza się na Opus 4.8, a Mythos 5 działa z częścią zabezpieczeń zdjętą i trafia tylko do zweryfikowanych partnerów cyberobrony przez Project Glasswing.
Ile kosztuje Claude Fable 5?
10 $ za milion tokenów wejściowych i 50 $ za milion wyjściowych, dokładnie dwa razy tyle co Opus 4.8 (5 $ i 25 $). Do 22 czerwca 2026 jest darmowy w planach Pro, Max, Team i Enterprise na stanowiska; rozliczanie za użycie rusza 23 czerwca.
Czy Claude Fable 5 jest lepszy od Opusa i Sonneta?
Na moim własnym benchmarku, audycie repo tej strony punktowanym względem ręcznie zweryfikowanego klucza odpowiedzi, Fable 5 wziął 8.5 z 11 punktów przy 8.0 dla Opus 4.8 i 1 dla Sonnet 4.6, i jako jedyny zgarnął całą warstwę failovera. Na koszcie znalezionego buga Opus 4.8 wygrał z dużym zapasem: 0,11 $ wobec 0,30 $, łapiąc prawie tyle samo za jedną trzecią ceny. Sztandarowa liczba samego Anthropic to SWE-Bench Pro: 80,3% dla Fable 5 wobec 69,2% dla Opus 4.8. Wszystko to traktuj jako wsad do własnego evala, nie jako werdykt.
Czemu na moje zapytanie do Fable 5 odpowiedział Opus 4.8?
Fable 5 nie odmawia przy oznaczonych tematach, tylko po cichu odpowiada jako Opus 4.8. Według Anthropic dotyczy to mniej niż 5% sesji. Jeśli puszczasz pętle agentowe albo evale, loguj, który model odpowiedział, inaczej twoje liczby mieszają dwa modele.
Źródła i dalsza lektura
Źródła pierwotne
Strony samego Anthropic plus zewnętrzne evale cytowane w dniu premiery.
Pełny wpis Anthropic o Fable 5 i Mythos 5.
Szczegóły testów bezpieczeństwa i możliwości stojące za deklaracjami.
Współpraca z rządem USA w obszarze cyberobrony.
Wcześniejszy odczyt krzywej możliwości cyber.
Eval kodowania, w którym Fable 5 ma być na szczycie.
Praca cytowana jako potwierdzenie jednej z hipotez Mythosa.
Jeśli chcesz kontekstu operatora wokół tego tematu, pisałem już o Claude Code jako stacku agentów GTM i o stacku produkcyjnym AI, na którym realnie wydaję. Zasada ta sama co tutaj: model to jedna warstwa, system wokół niego to jest robota.