Most AI adoption frameworks are built for demos, not for teams
Growth teams try AI, nothing sticks, six months later they are back to the old workflow. The problem is not capability. It is integration. Here is the framework I use instead.
GTM Architect & Growth Operator · Now · 14 February 2026
TL;DR · Key insights
- Start with workflow diagnosis, not tool selection: most AI projects fail at adoption, not capability
- The highest-value AI use cases are repetitive, judgment-light, and currently handled by expensive humans
- Responsible rollout means keeping humans in the loop where the stakes are real
- Compounding value comes from connected systems, not isolated prompt experiments
Every growth team I’ve worked with has an AI problem that looks like an adoption problem.
They’ve tried the tools. ChatGPT for copy, Perplexity for research, a couple of internal prompts. Some things worked, most things didn’t, and nothing compounded. Six months later, they’re back to the old workflow with a few tabs open that they occasionally use.
The failure mode isn’t capability. It’s integration.
Why most AI adoption frameworks don’t work
The standard framework is: identify use cases, run pilots, scale what works. It sounds reasonable. It fails because:
It optimizes for novelty. Teams pick the shiny use case (generate blog posts! summarize calls!) rather than the high-leverage one (enrich every inbound lead in 90 seconds before the SDR calls).
It ignores workflow friction. The tool might work but the habit doesn’t form because the trigger is wrong. AI tools that require you to start them manually get used once a week. AI tools wired into the moment of need get used every day.
It underestimates the cost of low-quality outputs. A bad AI draft that an SDR sends becomes a bad outbound sequence. The downstream cost is real. The pilot metrics don’t capture it.
The framework I use
- Workflow audit
Map high-frequency, high-cost tasks. Not 'where could AI help' but 'where does the team spend time on repetitive, judgment-light work currently handled by expensive humans?'
- Prioritize by leverage
Score use cases on frequency, cost, and AI fit. The highest scorers are your first cohort.
- Wire it in
Build for the existing workflow trigger, not alongside it. 'Open ChatGPT and paste' won't stick. 'Lead hits inbound → enrichment runs' sticks.
- Human-in-the-loop
Define where human judgment is load-bearing: AI generates + human reviews (high-stakes), spot-checks (medium), or no review (low-stakes).
- Connect the outputs
Every AI step should produce something another step can use. Isolated experiments don't compound.
Step 1: Workflow audit
Map the team’s current high-frequency, high-cost tasks. Not “where could AI help”: “where does the team spend time on work that is repetitive, judgment-light, and currently handled by expensive humans?”
That’s the target. Everything else is secondary.
Step 2: Prioritize by leverage, not excitement
The highest scorers are your first cohort. Usually this is: lead enrichment, content personalization, email sequencing, competitive monitoring, report generation.
Step 3: Wire it in, don’t bolt it on
The difference between an AI use case that compounds and one that gets abandoned is whether it’s wired into an existing trigger.
If the trigger is “open ChatGPT and paste the thing,” it won’t stick. If the trigger is “Salesforce lead hits inbound → enrichment runs automatically → SDR sees a completed profile,” it sticks because there’s no extra step.
Build for the existing workflow, not alongside it.
Step 4: Human-in-the-loop for anything that matters
Not every AI output should go directly to a customer. The responsible rollout model:
- AI generates, human reviews → for high-stakes output (proposals, pricing, escalation emails)
- AI generates, human spot-checks → for medium-stakes output (outbound sequences, meeting summaries)
- AI generates, no review needed → for low-stakes output (internal summaries, tagging, enrichment)
Define these categories explicitly. The team needs to know where their judgment is load-bearing.
Step 5: Connect the outputs
Isolated AI experiments don’t compound. The meeting summary that goes nowhere isn’t valuable. The meeting summary that auto-creates a CRM note, flags an action item, and triggers a follow-up sequence: that’s a system.
Build toward connected outputs from the start. Every AI step should produce something another step can use. I’ve written about the specific agent stack that runs this and why CRM-first beats prompt-first when sequencing adoption decisions.
What this looks like in practice
At a B2B SaaS company running outbound, the first cohort of AI use cases usually looks like:
- ICP scoring on inbound leads (automatic, no review)
- Company research brief before SDR call (AI generates, SDR reads)
- First-draft email personalization (AI generates, SDR edits before sending)
- Call summary → CRM note (automatic, manager spot-checks weekly)
These four things compound because each one feeds the next, instead of sitting in its own tab.
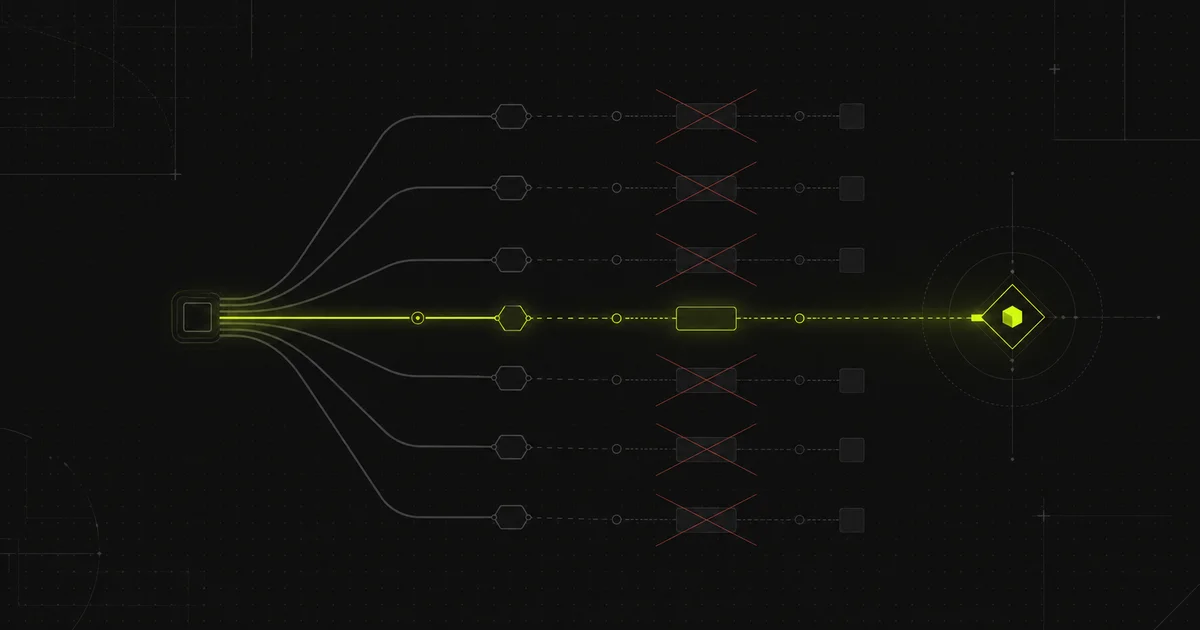
One chain, not four separate tools
ICP scoring runs on arrival, no review needed
SDR reads a finished profile before the call
SDR personalizes the draft, then sends
Call summary lands, manager spot-checks weekly
The value is in the arrows, not the boxes. Each step hands the next something it can use, so the work accrues instead of resetting.
Lead quality
↑
SDR prep time
↓
CRM hygiene
↑
Coaching data
↑
That’s the model. Not AI everywhere: AI in the right four places, connected correctly.
Related: B2B SaaS Growth System: from ICP clarity to connected acquisition and retention · GTM Tools: Build vs Buy Decision Framework for Operators